AI-аналитик безопасности — автоматическая сортировка и расследование алертов
У команд безопасности нет дефицита алертов. Дефицит — во времени на их разбор.
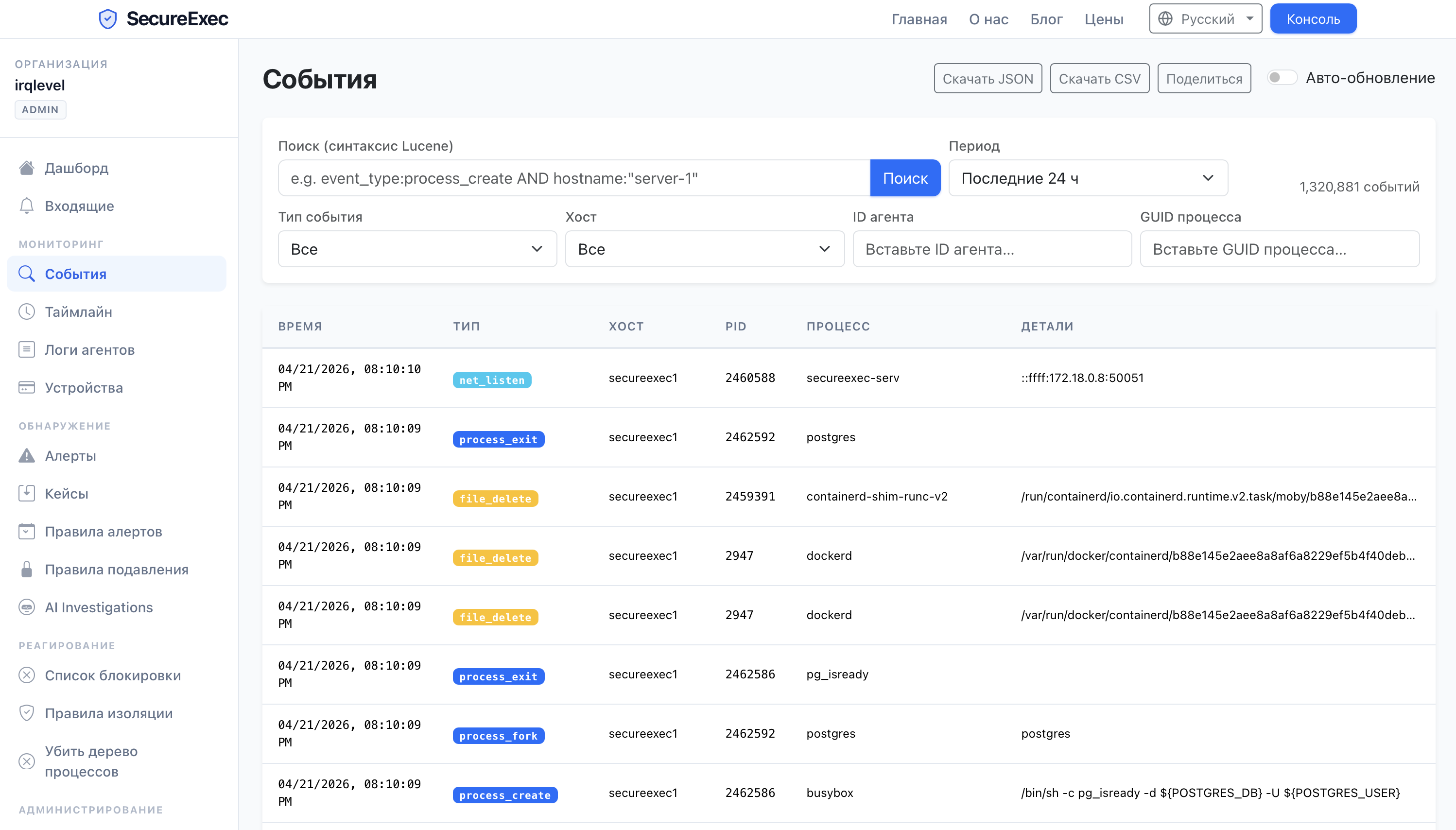
Типичная продакшн-среда с endpoint-детектированием генерирует от десятков до сотен алертов в день. Большинство оказываются безобидными: контейнерный рантайм переключает namespace, мониторинговый скрипт обращается к чувствительному файлу, легитимная админская сессия подходит под паттерн brute-force. Каждый из них всё равно требует от аналитика открыть алерт, собрать контекст, проверить дерево процессов, сопоставить недавнюю активность и принять решение. Даже у опытного оператора на это уходит 10–30 минут.
Арифметика не сходится. Когда очередь растёт быстрее, чем команда успевает разбирать, реальные угрозы остаются непросмотренными. Наступает alert fatigue. Аналитики начинают просматривать по диагонали, а не расследовать. Время присутствия атакующего в инфраструктуре растёт.
Почему простая автоматизация не спасает
Стандартный ответ индустрии — автоматизация: SOAR-плейбуки, подавление по severity, статические пайплайны обогащения. Это помогает, но быстро упирается в потолок.
Подавление по порогу («игнорировать все medium-алерты от этого правила») рано или поздно отбросит true positive, совпавший с паттерном подавления. Статические плейбуки («если тип алерта X — выполнить скрипт Y») могут обогатить алерт контекстом, но не способны рассуждать о том, делает ли этот контекст алерт безобидным или опасным. Они не могут сказать: «Этот вызов setns похож на попытку container escape, но дерево процессов показывает, что его инициировал runc в рамках штатной Docker-оркестрации на хосте, который запускает контейнерные нагрузки — это ожидаемое поведение».
Такое рассуждение требует понимания контекста, а не просто совпадения паттернов.
Как работает AI-аналитик SecureExec
SecureExec включает встроенного AI-аналитика, который расследует алерты так же, как это делает живой SOC-аналитик — собирает улики, изучает контекст и формирует заключение.
Под капотом аналитик запускает ReAct-агент (Reasoning + Acting) на базе любой OpenAI-совместимой LLM. Это не простая система «промпт — ответ». Агент имеет доступ к набору инструментов расследования и сам решает, какие из них вызвать, исходя из того, что уже нашёл:
- Детали алерта — читает полный алерт со всеми связанными событиями, метаданными правила и вердиктами threat intelligence.
- Дерево процессов — обходит цепочку выполнения: что породило подозрительный процесс, кто его родитель, какие дочерние процессы он создал.
- Поиск событий — запрашивает временную шкалу событий вокруг алерта, чтобы найти подтверждающие или оправдывающие данные: сетевые соединения, изменения файлов, смену привилегий.
- Контекст хоста — проверяет ОС, роль, теги, версию агента и статус изоляции хоста.
- История алертов — ищет повторяющиеся паттерны на том же хосте или от того же правила, чтобы отличить разовую аномалию от постоянного шума.
В ходе конкретного расследования агент вытягивает, например, полное дерево процессов и временную шкалу событий вокруг алерта и рассуждает прямо над ними — те же представления, которые аналитик открыл бы вручную:
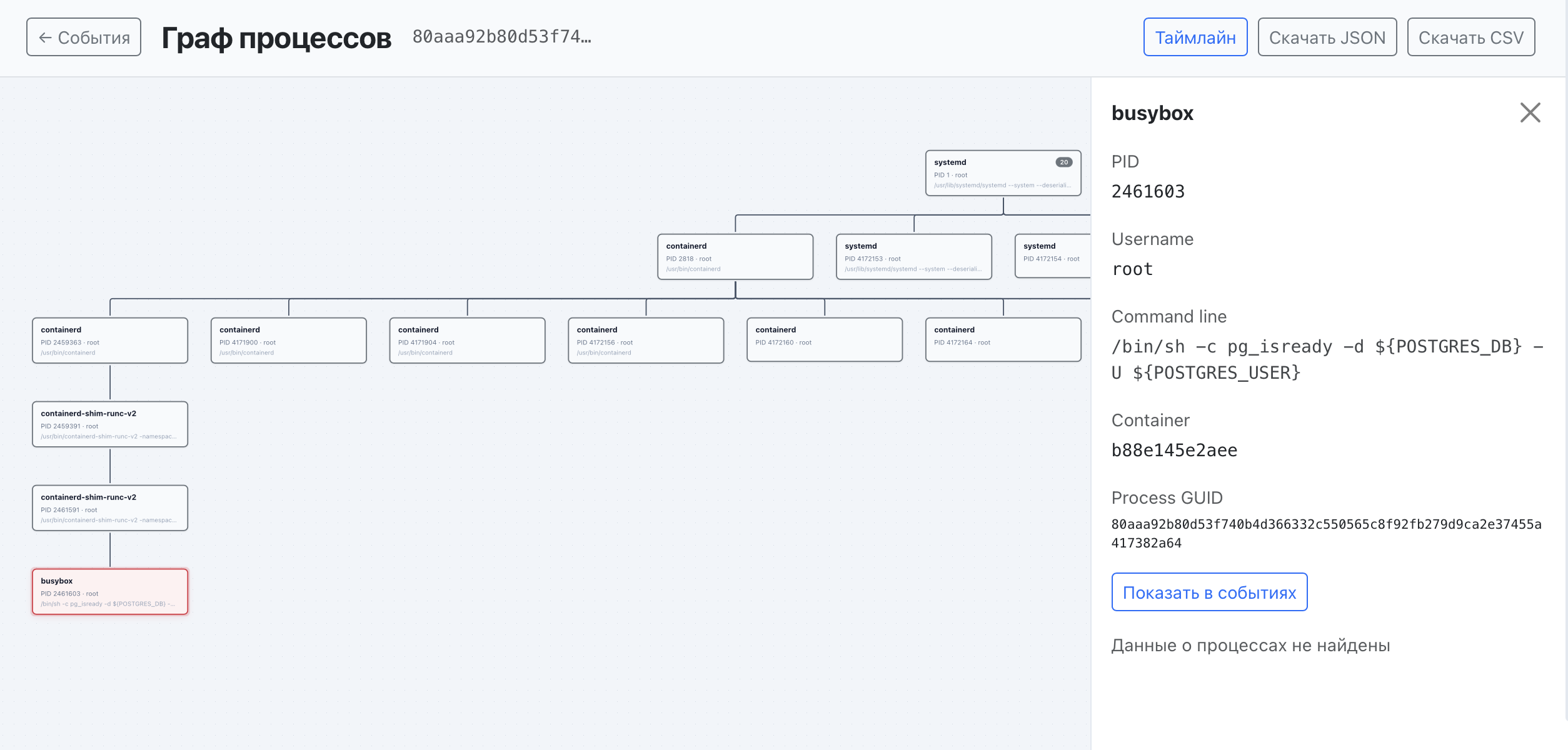
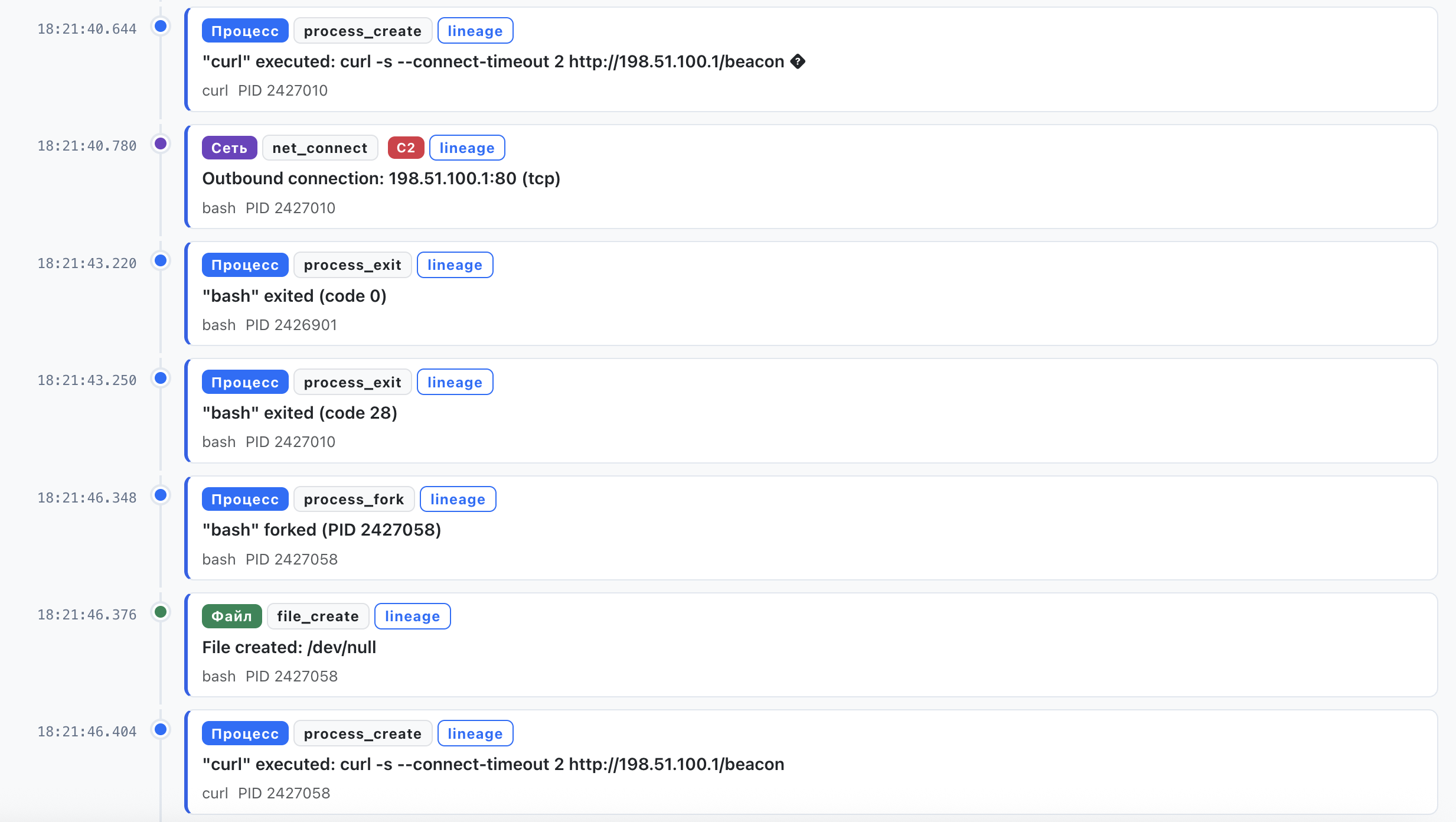
Агент проходит через эти инструменты по мере необходимости — обычно 3–7 вызовов за расследование — и затем формирует структурированный вердикт:
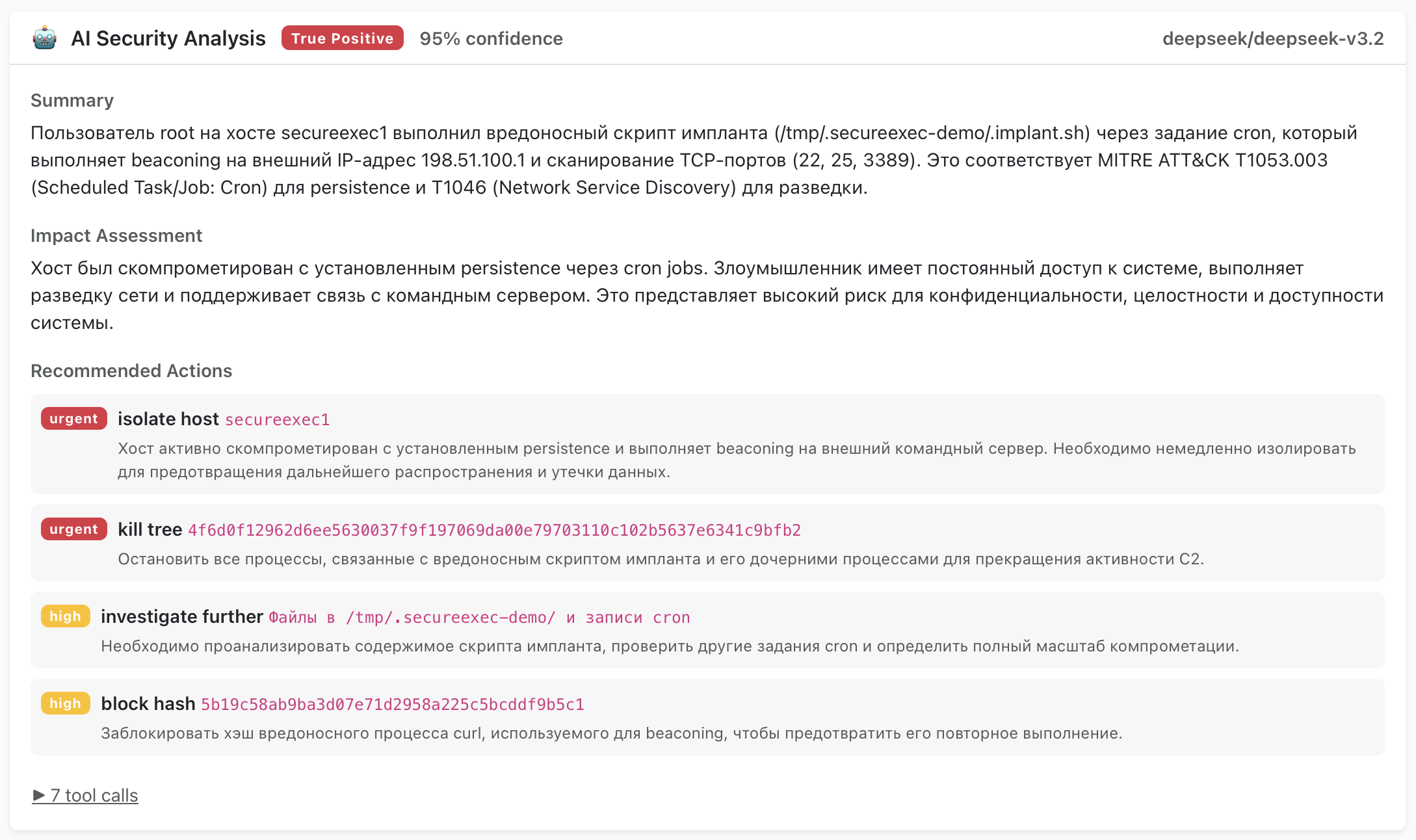
- Вердикт:
true_positive,false_positive,needs_reviewилиinconclusive. - Уровень уверенности: 0–100, отражающий, насколько агент уверен в своей оценке.
- Резюме: объяснение в 2–4 предложениях — что произошло и почему вынесен такой вердикт.
- Оценка воздействия: каков потенциальный или подтверждённый ущерб.
- Рекомендуемые действия: конкретные следующие шаги — изолировать хост, убить дерево процессов, расследовать глубже, проверить доступы — каждый с приоритетом.
Прозрачность, а не чёрный ящик
Каждое расследование полностью аудируемо. В интерфейсе видно каждый вызов инструмента, какие аргументы агент использовал, какие данные получил и сколько времени занял каждый запрос. Если агент решил, что алерт — ложное срабатывание, вы видите, на каких именно данных он основал этот вывод.
Это важно, потому что доверие к автоматической сортировке зависит от возможности её проверить. Непрозрачный вердикт «AI говорит, что всё в порядке» бесполезен в контексте безопасности. А вердикт, подкреплённый видимой цепочкой доказательств — «я проверил дерево процессов, это runc выполняет штатную контейнерную оркестрацию, хост запускает Docker-нагрузки, это правило срабатывает 12 раз в день на этом хосте» — аналитик может просмотреть за секунды и либо подтвердить, либо пересмотреть.
Примеры из практики
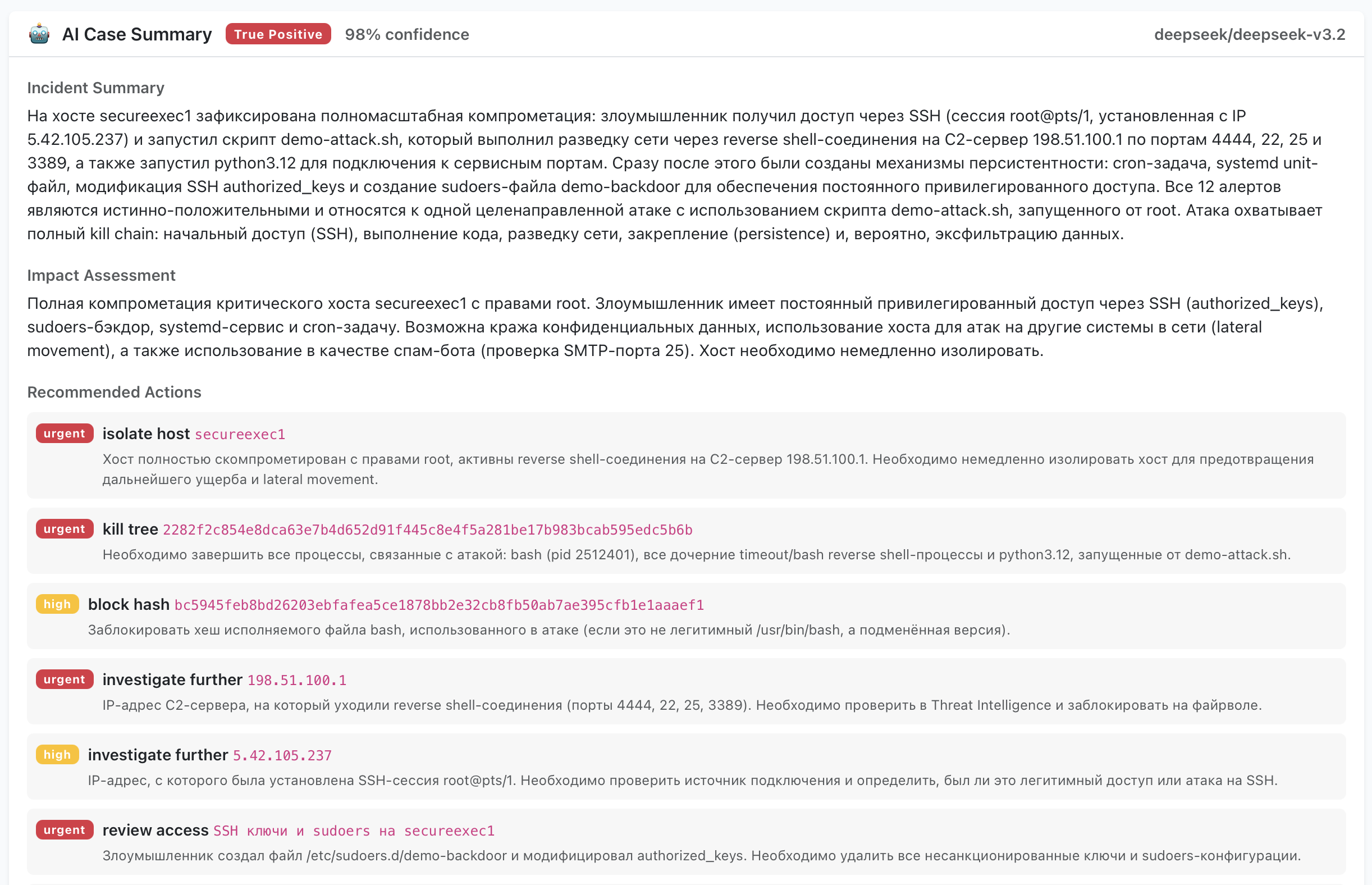
True positive — SSH brute-force атака. AI-аналитик идентифицирует систематическую brute-force атаку с конкретного IP, подтверждает соответствие известным паттернам атак и рекомендует заблокировать источник, проверить конфигурацию SSH и расследовать возможные успешные входы.
False positive — смена namespace контейнера. Вызов setns срабатывает по правилу обнаружения container escape. AI-аналитик проверяет дерево процессов, видит, что вызов инициирован runc init в рамках штатной Docker-оркестрации, и корректно классифицирует как ожидаемое поведение.
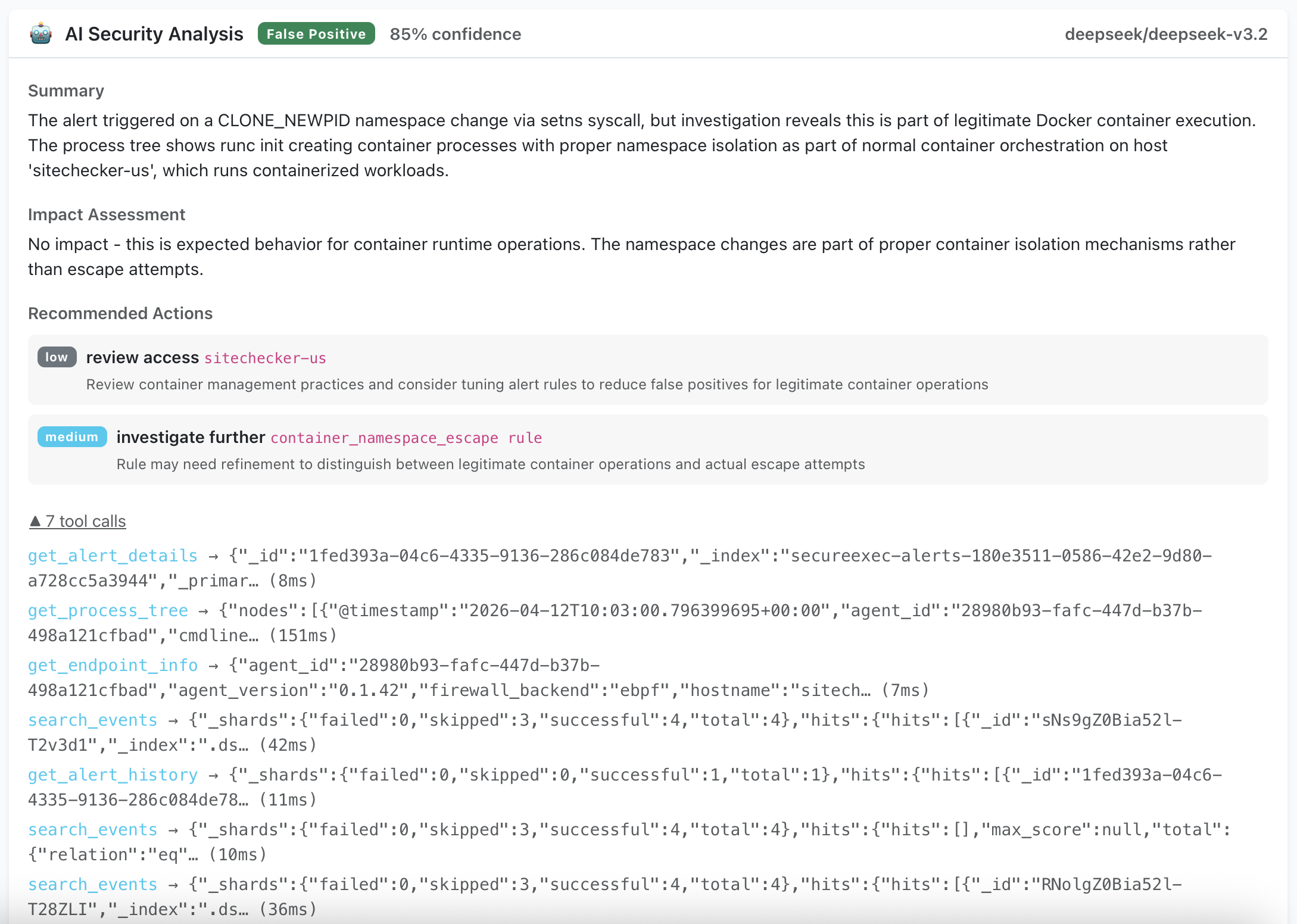
В обоих случаях видна полная цепочка вызовов инструментов — какие данные запросил агент, что получил и как пришёл к заключению.
Ваша модель, ваши данные
AI-аналитик SecureExec работает с любым OpenAI-совместимым API. Вы можете направить его на:
- Облачный API — например, OpenRouter, где доступны модели от Anthropic, Google, Meta, DeepSeek и других.
- Локальную модель — работающую на вашем оборудовании через Ollama, vLLM или любой другой OpenAI-совместимый сервер.
При использовании локальной модели ни один байт данных об алертах не покидает вашу инфраструктуру. LLM работает в вашей сети, запрашивает ваш Elasticsearch через те же внутренние API, что и веб-панель, и записывает вердикт обратно в вашу базу данных. Для сред со строгими требованиями к резидентности данных или комплаенсу — это единственная жизнеспособная архитектура для AI-сортировки.
Практический рабочий процесс
AI-аналитик встраивается в существующий рабочий процесс тремя способами:
Автоматическая сортировка. Когда включена, каждый новый алерт выше настраиваемого порога severity автоматически расследуется. Вердикт появляется на алерте за секунды, ещё до того, как его откроет человек. Аналитики могут начинать смену с алертами, уже рассортированными на «подтверждённые угрозы», «вероятные ложные срабатывания» и «требует ручной проверки» — вместо неразобранной очереди.
Связанные алерты с одного хоста, приходящие в коротком временном окне, объединяются в один AI-кейс — так вердикт, резюме и рекомендуемые действия выдаются один раз на инцидент, а не повторяются для каждого алерта:
Ручное расследование. Любой алерт или кейс можно расследовать по запросу одним кликом. Полезно для алертов, поступивших до включения авто-сортировки, или когда аналитик хочет получить второе мнение по сложному кейсу.
Обогащённые уведомления. Когда AI-аналитик завершает расследование, уведомления в Telegram или Slack включают вердикт, уровень уверенности, резюме и рекомендуемые действия наряду со стандартными полями алерта. Аналитик, получивший уведомление, часто может принять решение по сортировке, не открывая панель.
Влияние на производительность команды
Прямой эффект — сокращение среднего времени расследования (MTTI). Алерты, на которые раньше уходило 15–30 минут ручного сбора контекста, сортируются меньше чем за минуту. Но эффекты второго порядка важнее:
- Младшие аналитики выходят на продуктивность быстрее. Вместо того чтобы учиться самостоятельно навигировать по логам событий и деревьям процессов, они изучают расследования AI и перенимают логику рассуждений. Лог расследования — по сути, учебный материал для каждого алерта.
- Старшие аналитики фокусируются на реальных инцидентах. Когда 80% очереди предварительно отсортировано как ложные срабатывания с видимыми доказательствами, старшие инженеры тратят время на 20%, которые действительно важны — подтверждённые угрозы, требующие сдерживания и устранения.
- Ночное и выходное покрытие улучшается. Авто-сортировка работает 24/7. Критический алерт в 3 ночи получает такое же качество первичного расследования, как и в 10 утра.
Начало работы
Настройка занимает менее пяти минут:
- Задайте три переменные окружения:
LLM_URL(endpoint вашей LLM),LLM_API_KEYиLLM_MODEL(например,anthropic/claude-sonnet-4,deepseek/deepseek-chatили имя локальной модели). - Включите AI-аналитика в разделе Администрирование > Настройки AI.
- Настройте порог severity для авто-сортировки (по умолчанию:
highи выше) и максимальное число одновременных расследований.
Аналитик работает с любой выбранной моделью. Более крупные модели дают более глубокий анализ; более компактные — быстрее и дешевле. Правильный баланс зависит от объёма алертов и бюджета. Начните с авто-сортировки для high и critical, просмотрите вердикты за несколько дней и скорректируйте настройки.